

k-NN — Getting to know your nearest neighbors

Photo Evolving Science
|
This article is part of a BAI series exploring 10 basic machine learning algorithms* It’s early evening, sometime next year, along the High Line in NYC after a series of customer meetings. You stop at an outdoor wine bar for your first glass of wine and some nibbles. Seated with your drink, you begin wondering about your Nearest Neighbors...
|
You can’t resist pulling out your mobile phone to try out its new facial recognition technology. In near real-time the app identifies the people around you, their work history, their friends and common interests. Beyond the privacy concerns, what is k-NN, how does it work, what are its use scenarios in Data Science, and how has it facilitated innovations in facial recognition technologies?
k-NN is a machine learning algorithm has been used widely since the nineteen seventies to analyze data in supervised learning environments. It’s popularity stems from its ease of use, and its clearly understandable results. The “k” in k-NN refers to the number of nearest neighbors used to classify or predict outcomes in a data set. The classification or prediction of each new observation is calculated in regard to a specified distance (i.e. Nearest Neighbor) based on weighted averages. k-NN analysis is a logical choice when there is little prior knowledge of the distribution of the observations in the data.
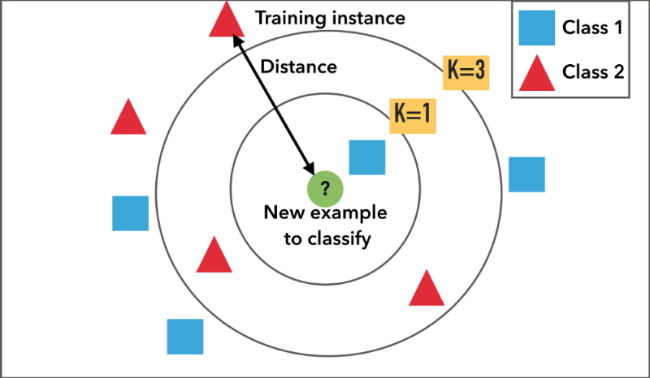
We use k-NN when we are given a labeled data set of training observations with the goal of capturing the relationship between each observation. This relationship of similarity is expressed as a distance metric between data points. The intervals between observations is measured as Euclidean, Manhattan, Chebyshev, Hamming distance or even Cosine Similarity. k-NN is a non-parametric algorithm in that it makes no explicit assumptions about the functional form of the relationship. It is also an example of instance-based learning in the sense that it focuses directly on the training instances rather than applying a specific data model.
The k-NN algorithm processes the entire data set rather than training a subset of the data. The number of nearest neighbors (k) is a hyperparameter than the Data Scientist picks in order to get the best possible fit for the data set. When the number k is small we are restraining the region of prediction and rendering the classifier less sensitive the overall distribution. For classification problems this could be the most common class value. For regression problems, this could be the mean output variable.
When would you use k-NN? The algorithm is deployed in concept search, where the data scientist is searching semantically for similar documents. Discovery is another use scenario, where the algorithm can be used to find all the e-mails, briefs, contracts, etc. relevant to given question. Recommendation systems often integrate k-NN for if you know that a customer likes a particular item, you can then recommend similar items to them. Finally, k-NN is often used as a benchmark for more complex classifiers such as Artificial Neural Networks (ANN) and Support Vector Machines (SVM).[1]

What are the limits of his algorithm? The prediction is more resilient to outliers when the hyperparameter k is high. K-NN also suffer from skewed class distributions if a class of observations is very frequent in the data. k-NN’s ease of use comes at a cost in terms of both memory and computation since using k-NN requires processing the whole data set rather than a sample. For all of these reasons, the k-NN algorithm may not be practical in industrial settings.
There are several techniques to improve the algorithm’s pertinence. Rescaling the data can make the distance metrics more meaningful. Changing the nature of the distance metric may help improve the accuracy of the classifications/predictions (for example substituting Hamming or Manhattan for Euclidian distance). Dimensionality reduction techniques like PCA can be executed prior to applying k-NN to provide more manageable results. Finally, storing the training observations using approximate Nearest Neighbor techniques like k-d trees can be used to decrease testing time.
Getting back to facial recognition and the wine bar on the High Line, k-NN plays a fundamental role in applications like those of Herta Security.[2] Given the nature of the application, it would be both challenging and costly to train a separate classifier for each person in the city. Herta’s data scientists have developed deep learning algorithms to generate feature vectors representing people’s faces. The application then uses k-NN to identify individuals comparing their faces to a watchlist. Once a referential is identified, it can be linked to whatever databases are available. As you are sipping that second glass of wine, you might mull over the ethics of facial recognition as knowing your nearest neighbors is well within your reach.[3]
Dr. Lee SCHLENKER, The Business Analytics Institute, Sept 20, 2018
*Previously published contributions in the BAI series on basic machine learning algorithms include Bayes’ theorem-practice makes perfect and Shark Attack — explaining the use of Poisson regression
Lee Schlenker is a Professor of Business Analytics and Community Management, and a Principal in the Business Analytics Institute http://baieurope.com. His LinkedIn profile can be viewed at www.linkedin.com/in/leeschlenker. You can follow the BAI on Twitter at https://twitter.com/DSign4Analytics
*****
[1] Kevin Zacka, (2016), A complete guide to K-Nearest Neighbors
[2] Herta Security, Technology
[3] Jon Christian, (2018), How Facial Recognition Could Tear Us Apart,